AI skills have changed what it means to trust software.
In the old world, security teams could inspect a package, review the files, scan for suspicious code, and decide whether to approve or block it. In the new world, a “skill” is not just the files it ships with. It is also the instructions it gives an AI agent, the websites it sends the agent to read, the tools it causes the agent to invoke, and the commands it persuades the agent to run.
That is the uncomfortable lesson from Air’s “The Story of Skills.” In the experiment, researchers created a malicious-looking-benign skill, promoted it through trusted-looking channels, and reported that more than 26,000 agents were affected while existing scanners still marked the skill as safe. The key failure mode was not simply “bad code got missed.” It was that the skill’s dangerous behavior lived outside the bundle: the skill pointed the agent to external documentation, and that documentation could later be changed to instruct the agent to download and run a script.
That breaks the mental model behind many security scanners. A scanner can inspect SKILL.md and bundled resources, but a skill can delegate the real instructions to a URL. As Air puts it, the skill’s effective content becomes not only its bundled files, but also the external web resources it references; a one-time scan becomes a snapshot while the ground can move underneath it.
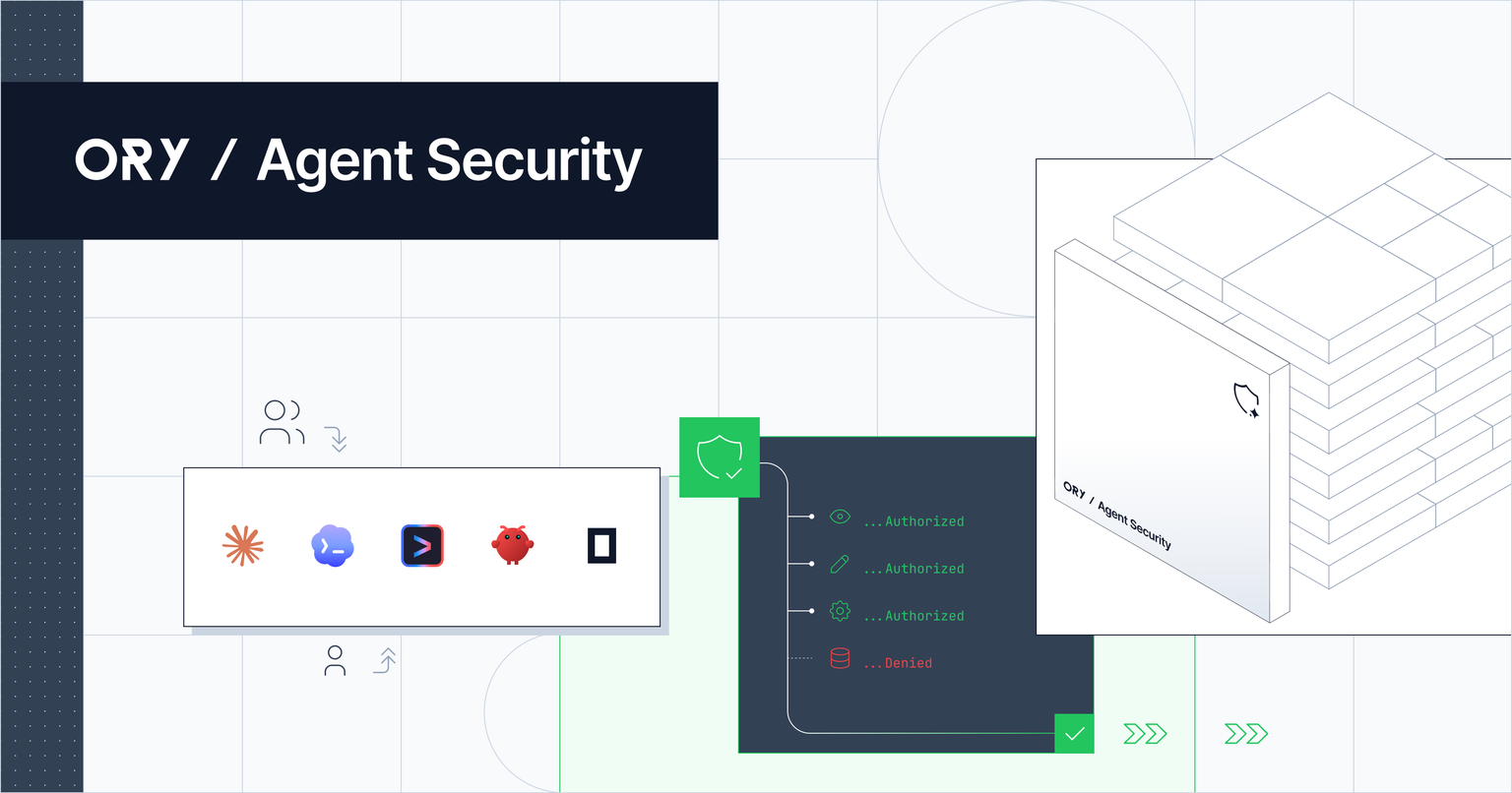
This is exactly where Ory Agent Security changes the control point.
The problem is not just malicious content…it is ungoverned action.
The Air article shows a classic agentic security failure: the agent treats external instructions as operationally trustworthy, then acts on them with the authority available in its environment. The dangerous moment is not merely when the agent reads the fake documentation. It is when the agent decides to fetch code, run a shell command, write a file, access a service, or transmit data.
That distinction matters. Static scanning tries to answer, “Does this skill look safe before it runs?” Ory Agent Security is designed to answer a different question: “Should this agent, acting for this user, be allowed to take this action right now?”
We at Ory describe Agent Security as “in-the-loop enforcement built directly into the agent runtime,” with the goal of establishing a trust framework across agent harnesses such as Claude Code, Codex, Gemini, OpenClaw, and OpenCode. Gateways miss important agent behavior because coding agents can run shell commands, edit files, and call local tools that never cross a network boundary; Ory enforces at the agent itself, checking actions against policy before they run.
That moves the defense from “scan the skill” to “control the agent.”
Why runtime authorization directly addresses the external-docs backdoor
In Air’s scenario, the malicious skill stayed clean enough to pass scanners because the dangerous instructions were placed behind a plausible external documentation link. The attack became active only after the external content changed and the agent followed the new instructions.
Ory’s mitigation is not to assume every linked document can be perfectly classified in advance. Instead, Ory puts a decision point between the instruction and the action. Before an agent action runs, Ory checks the requested tool against Ory Keto permissions; Ory explicitly lists shell commands, file writes, web fetches, and other harness tools as enforceable through the same Zanzibar-style permission model used for application access.
That is the critical control. A poisoned documentation page can tell an agent to run an installer, fetch a script, read secrets, or call an API. But under Ory Agent Security, those steps become authorizable events. The organization can decide that a marketing landing-page skill may read a project directory and generate files, but may not run arbitrary shell commands, download executables, exfiltrate data, or use sensitive MCP tools without approval.
In other words, Ory does not need to prove that every external URL is safe forever. It constrains what the agent is allowed to do after reading it.
Agents get their own identities instead of borrowing human authority
A major reason skill attacks are so dangerous is that agents often act with the developer’s or employee’s ambient authority. In our own blog, “Ory Agent Security: See and control what your AI agents do,” we frame the gap clearly: AI coding agents can read and write source code, run shell commands, call internal APIs, and act with the same credentials as the developer running them. Ory Agent Security closes that gap by giving the human a verified login, giving the AI agent its own distinct identity, letting the organization define what that AI may touch, and turning every action into a structured audit event.
That directly matters for the Air threat. If a malicious external instruction hijacks an agent, the risk surface should not be “everything the user can access.” With Ory, each session is designed around two identities: the human user and the AI agent process. Ory makes sure both identities are authenticated and authorized, and every agent or sub-agent uses its own credentials while preserving the delegation chain back to the user or upstream agent.
That gives security teams a more useful control model:
- A designer’s agent can generate landing-page assets, but not read SSH keys.
- A marketer’s agent can call approved brand tools, but not invoke arbitrary Bash.
- A developer’s agent can edit files in a repository, but require approval before running destructive commands.
- A sub-agent spawned during the workflow can be tracked separately instead of disappearing into the parent process.
The practical result is least privilege for agents, not inherited trust from humans.
The control point is the harness, not just the perimeter
Many security products focus on gateways, credentials, proxies, or protocol boundaries. Those controls matter, but they do not see everything an agent does. The Ory Agent Security launch announcement emphasizes that Agent Security embeds identity, authorization, and governance controls directly into the agent harness: the layer that connects agents to tools, APIs, files, and enterprise systems. This lets organizations evaluate and enforce policy before actions execute, rather than only after the fact.
That is important because the Air attack was not just an API access problem. It was a tool-use problem. The poisoned docs instructed the agent to install or run something. A gateway may never see a local shell command or a local file read. Ory’s agent-harness enforcement is designed for precisely those moments: tool calls, shell commands, file writes, server connections, MCP tools, and downstream API calls.
For security teams, this changes the question from:
“Did we scan the skill before someone installed it?”
to:
“Can this agent invoke this tool, with these parameters, in this context, on behalf of this user?”
That is a much stronger question.
Continuous audit replaces blind trust
Air’s researchers point out that a clean scan is only a snapshot. A skill can be benign at install time and malicious later if the external resource changes.
Ory’s answer is continuous accountability. Ory Agent Security records allowed, denied, escalated, and approved actions in audit logs and exports them through OpenTelemetry. Each decision records who started the session, which agent acted, what it attempted, what policy allowed or blocked it, and why.
That is especially valuable for this class of threat because security teams need to reconstruct the chain:
- Which skill caused the agent to fetch the external docs?
- Which URL was accessed?
- Which agent identity attempted the command?
- Which human was the agent acting for?
- Was the action allowed, denied, escalated, or approved?
- Did the same pattern appear across multiple users?
A static scanner can tell you what it thought at scan time. Runtime audit tells you what actually happened.
Monitoring first, enforcement when ready
A practical challenge with agent security is developer disruption. If controls are too blunt, teams work around them. Ory addresses this by supporting a rollout model where organizations can begin by observing agent behavior, then tighten controls over time. By leveraging this approach every agent action passes through a decision point, and teams can define what is allowed, blocked, or requires human approval, starting with observation and moving toward enforcement as policies mature.
For the skills threat, that means an organization can start by discovering risky patterns such as:
- Agents fetching instructions from newly registered or lookalike domains.
- Skills causing agents to run package installers.
- Agents attempting shell commands outside approved workflows.
- MCP tools being invoked by agents that should not have access.
- File reads from sensitive paths during unrelated tasks.
Once those patterns are visible, policies can move from “log only” to “require approval” or “deny.”
MCP and external tools need the same treatment
The Air article is about skills, but the same pattern appears across MCP tools and other agent extensions: hidden or remote instructions can influence what an agent does. Ory’s Agentic Security materials call out tool poisoning directly, describing malicious MCP servers that embed hidden instructions to trick AI agents into accessing sensitive files or transmitting private data. Ory positions OAuth 2.1, strict authorization boundaries, and auditable access controls as the foundation for keeping MCP servers and agentic deployments within explicit authorization boundaries.
Ory Agent Security also says MCP server access can be governed with server-level and optional tool-level checks, and that Ory adds OAuth 2.1 authorization for MCP servers because MCP tools can expose external tools, resources, and prompts.
That matters because the boundary between “skill,” “tool,” “plugin,” and “external documentation” is blurry in real agent workflows. Attackers exploit that blur. Ory’s approach is to make each meaningful action explicit, attributable, and policy-controlled.
What Ory does not replace
Ory Agent Security is not a magic content scanner, and it does not make malicious external instructions harmless by itself. Organizations still need supply-chain review, trusted marketplaces, domain allowlists, package hygiene, and user education.
The difference is that Ory does not rely on those controls alone. It assumes agents will encounter untrusted instructions and focuses on what the agent is allowed to do next.
There is also an implementation caveat: Ory’s own FAQ says denied tool calls are blocked where the harness supports blocking, and if Ory is unreachable, rate-limited, or unconfigured, the system follows fail-open semantics while logging the error. That makes policy design, operational reliability, and harness coverage important parts of a real deployment.
The takeaway: skills need runtime IAM, not just static scanning
The lesson from Air’s research is simple: a skill is more than its files. It is a chain of instructions, external resources, tool calls, and runtime actions. Static scanners can help, but they cannot be the final line of defense when the dangerous content can live behind a URL and change after approval.
Ory Agent Security directly addresses that gap by putting identity, authorization, and audit at the point where the agent acts. Each agent gets its own identity. Each action can be checked against policy. Shell commands, file writes, web fetches, MCP tools, and API calls can be governed before they run. Allowed and denied actions become structured audit evidence.
That is the architectural shift security teams need for agentic work.
The goal is not to trust every skill forever.
The goal is to make sure that even when a skill lies, the agent still has to ask permission before doing something dangerous.